持续更新中,原文档:https://docs.dependencytrack.org/
目录
介绍
开始
部署
Docker
Executable WAR
WAR
初始化
配置
数据库支持
数据目录
LDAP配置
OpenID连接配置
使用
集成和交付
透明度
因素分析
策略遵从
采购
分析类型
已知漏洞分析
过时组件分析
许可证评估
组件标识
完整性验证
数据源
NVD
NPM Public Advisories
Sonatype OSS Index
VulnDB
Datasource Routing
库文件
内部组件
私有漏洞库
报告结果
审计
状态
抑制
集成
初始化
初始化时会进行以下操作:
生成默认对象,如用户、团队、权限
生成用于JWT令牌创建和验证的密钥
加载CWE和SPDX license数据
加载漏洞数据源的镜像(NVD、NPM Advisories等)
默认管理员账户
username:admin
password:admin
第一次登录,需要更改密码。
配置
后端
默认情况下,配置文件application.properties在WAR的classpath中。可配置众多性能调整参数,最关键是外部数据源、目录服务(LDAP)和代理设置。
对于容器化部署,配置文件中定义的属性也可以指定为环境变量。所有环境变量都是大写的,句点(.)替换为下划线(_)。有关使用环境变量的配置示例,请参阅Docker说明。
默认的嵌入式H2数据库设计用于快速评估和测试。不要在生产环境中使用嵌入式H2数据库。
请参阅:数据库支持。
如果需要使用自定义配置启动,请在执行时添加系统属性alpine.application.properties,例如:
|
默认配置
|
代理配置
代理支持以下两种方式进行配置,使用application.properties中定义的代理设置或通过环境变量。默认情况下,系统将尝试读取 https_proxy,http_proxy 和 no_proxy环境变量。如果他们被设置,Dependency-Track将自动使用。
no_proxy指定的URLs将会从代理中被排除。可以是以逗号分隔的主机名、域名或两者的混合列表。如果为某个URL指定了端口号,则只有具有该端口号的请求才会被排除在代理之外。不能将no_proxy设置为单个星号(“*”)以匹配所有主机。
支持需要BASIC、DIGEST和NTLM验证的代理。
日志记录等级
可以通过在启动时设置dependencyTrack.Logging.level系统属性来指定日志记录等级(INFO、WARN、ERROR、DEBUG、TRACE)。例如,以下命令将启动带有调试日志记录的Dependency-Track (embedded) :
|
对于Docker部署,只需将LOGGING_LEVEL环境变量设置为INFO、WARN、ERROR、DEBUG或TRACE。
前端
前端使用config.json文件,该文件通过 AJAX 动态请求和评估。文件位于 <BASE_URL>/static/config.json。
默认配置
|
对于容器化部署,这些设置可以通过以下任一方式覆盖:
- 将自定义的
config.json挂载到容器中/app/static/config.json - 将其作为环境变量提供
环境变量的名称与config.json中的对应名称相同。
挂载的config.json优先于环境变量。如果两者都被设定,则环境变量将被忽略。
数据库支持
默认包含嵌入式数据库H2。主要用于快速评估、测试和描述Dependency-Track平台的功能。
请不要在实际工作中使用默认数据库。
支持以下数据库:
- Microsoft SQL Server 2012 and higher
- MySQL 5.6 and 5.7
- PostgreSQL 9.0 and higher
数据库设置配置文件为application.properties,位于数据目录(data directory)中。
Microsoft SQL Server Example
|
MySQL Example
|
使用MySQL时,必须在创建数据库之前,从sql-mode中删除‘NO_ZERO_IN_DATE’ and ‘NO_ZERO_DATE’,以及添加 ‘ANSI_QUOTES’ 。具体请参照MySQL文档。
有多种方式改变MySQL配置文件,推荐使用以下方式(修改my.ini):
|
值得注意的是,MySQL会错误报告(“Specified key was too long”),实际上并没有。如果需要使用UTF-8,请不要使用MySQL。
PostgreSQL Example
|
数据目录
在UNIX/Linux上使用 ~/.dependency-track,在Windows上使用当前用户主目录的 .dependency-track 。该目录被称为数据目录(data directory),包括NIST NVD镜像,嵌入式数据库文件,审计日志以及部分密钥。应尽量提升数据目录安全性。
| 数据 | 用途 |
|---|---|
| db.mv.db | Embedded H2 database |
| dependency-track.log | Application log |
| dependency-track-audit.log | Application audit log |
| id.system | Randomly generated system identifier |
| index | Internal search engine index |
| keys | Keys used to generate/verify JWT tokens |
| nist | Mirror of the NVD and CPE |
| server.log | Embedded Jetty server log |
| vulndb | Mirror of VulnDB |
LDAP配置
Dependency-Track已在多种LDAP服务器上测试。下述内容为部分已测试可用于服务器默认模式的示例配置。
Microsoft Active Directory Example
|
ApacheDS Example
|
Fedora 389 Directory Example
|
NetIQ/Novell eDirectory Example
|
OpenID Connect配置
|
在OAuth2 / OIDC环境中,Dependency-Track的前端充当客户机(client),而API服务器充当资源服务器(resource server)(具体请参阅OAuth2 roles)。因此,前端需要额外的配置,目前只有在与API服务器分开部署时才支持这种配置。有关说明,请参阅配置和Docker部署页面。典型的Dependency-Track不支持仅使用WAR或excutable WAR部署!
如果配置正确,用户将可以通过OpenID 登录:
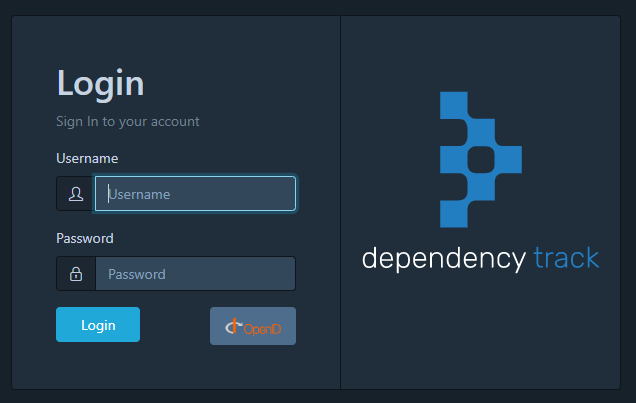
配置示例
Generally, Dependency-Track can be used with any identity provider that implements the OpenID Connect standard.下面是一些已知有效的配置示例。请注意,某些providers可能不支持某些特性,例如团队同步,或者需要修改配置文件。如果发现选择的provider无法与Dependency-Track一起使用,请提交issue。
有关前端和后端可用的完整配置设置,请参阅配置页面。
Auth0
| API server | Frontend |
|---|---|
| alpine.oidc.enabled=true | OIDC_CLIENT_ID=9XgMg7bP7QbD74TZnzZ9Jhk9KHq3RPCM |
| alpine.oidc.issuer=https://example.auth0.com | OIDC_ISSUER=https://example.auth0.com |
| alpine.oidc.username.claim=nickname | |
| alpine.oidc.user.provisioning=true | |
| alpine.oidc.teams.claim=groups* | |
| alpine.oidc.team.synchronization=true* |
*需要额外配置
GitLab (gitlab.com)
| API server | Frontend |
|---|---|
| alpine.oidc.enabled=true | OIDC_CLIENT_ID=ff53529a3806431e06b2930c07ab0275a9024a59873a0d5106dd67c4cd34e3be |
| alpine.oidc.issuer=https://gitlab.com | OIDC_ISSUER=https://gitlab.com |
| alpine.oidc.username.claim=nickname | |
| alpine.oidc.user.provisioning=true | |
| alpine.oidc.teams.claim=groups | |
| alpine.oidc.team.synchronization=true |
gitlab.com目前没有所需要设置的CORS headers,具体请参阅GitLab issue #209259.
对于内部安装,可以通过反向代理设置所需的headers来解决这个问题。
Keycloak
| API server | Frontend |
|---|---|
| alpine.oidc.enabled=true | OIDC_CLIENT_ID=dependency-track |
| alpine.oidc.issuer=https://auth.example.com/auth/realms/example | OIDC_ISSUER=https://auth.example.com/auth/realms/example |
| alpine.oidc.username.claim=preferred_username | |
| alpine.oidc.user.provisioning=true | |
| alpine.oidc.teams.claim=groups* | |
| alpine.oidc.team.synchronization=true* |
*需要额外配置,参阅Keycloak示例
Keycloak示例
以下步骤演示如何设置将OpenID Connect与Keycloak配合使用。大多数设置可以应用在其他idPs上。
This guide assumes that:
- the Dependency-Track frontend has been deployed to
https://dependencytrack.example.com- a Keycloak instance is available at
https://auth.example.com- the realm example has been created in Keycloak
如下所示配置客户端:
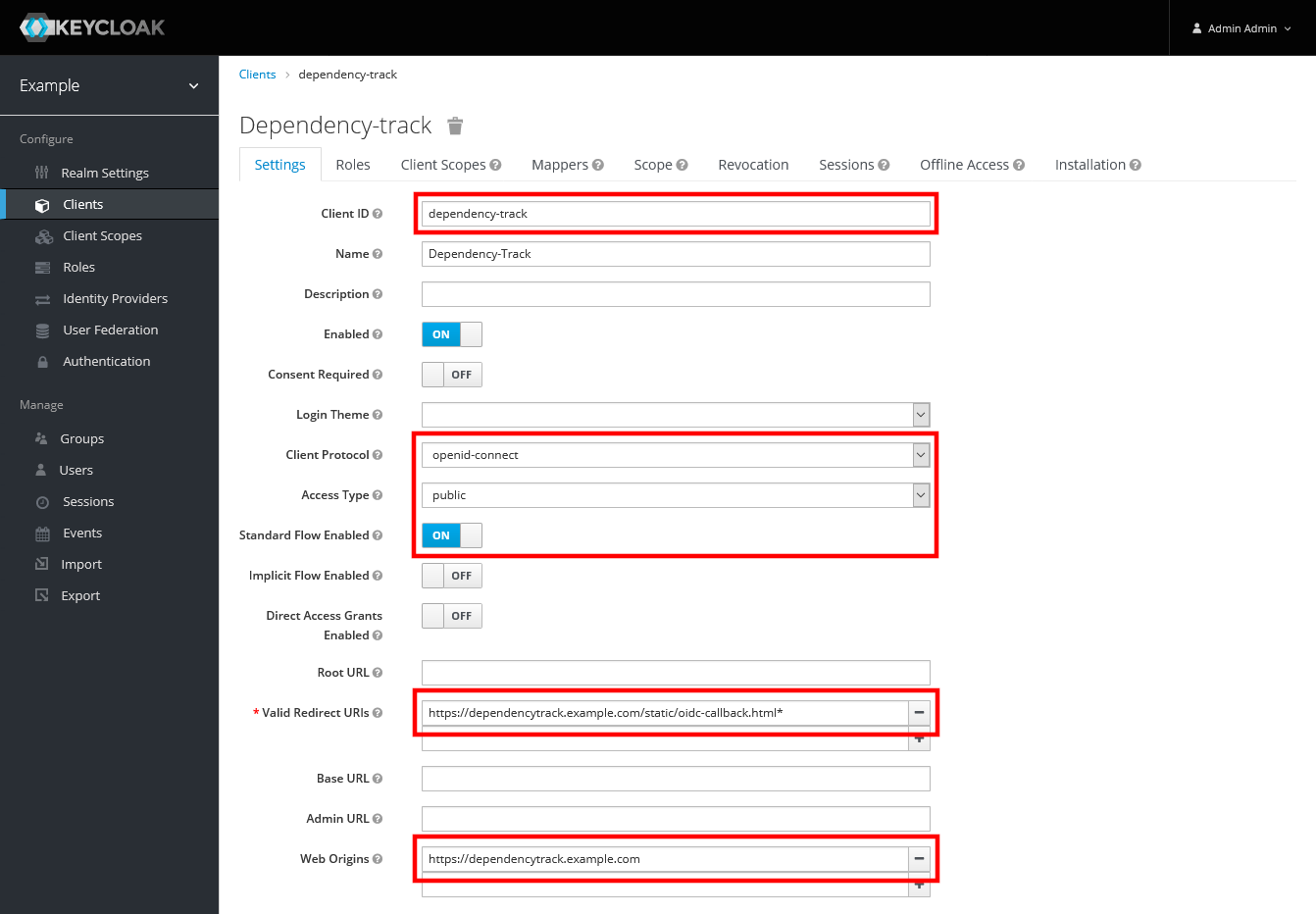
- Client ID:
dependency-track - Client Protocol:
openid-connect - Access Type:
public - Standard Flow Enabled:
ON - Valid Redirect URIs:
https://dependencytrack.example.com/static/oidc-callback.html* - The trailing
*is required when using the frontend v1.3.0 or newer, in order to support post-login redirects - Web Origins:
https://dependencytrack.example.com
- Client ID:
为了能够同步团队成员身份,需要创建一个protocol mapper,将组成员身份作为
groups包含在/userinfo端节点中: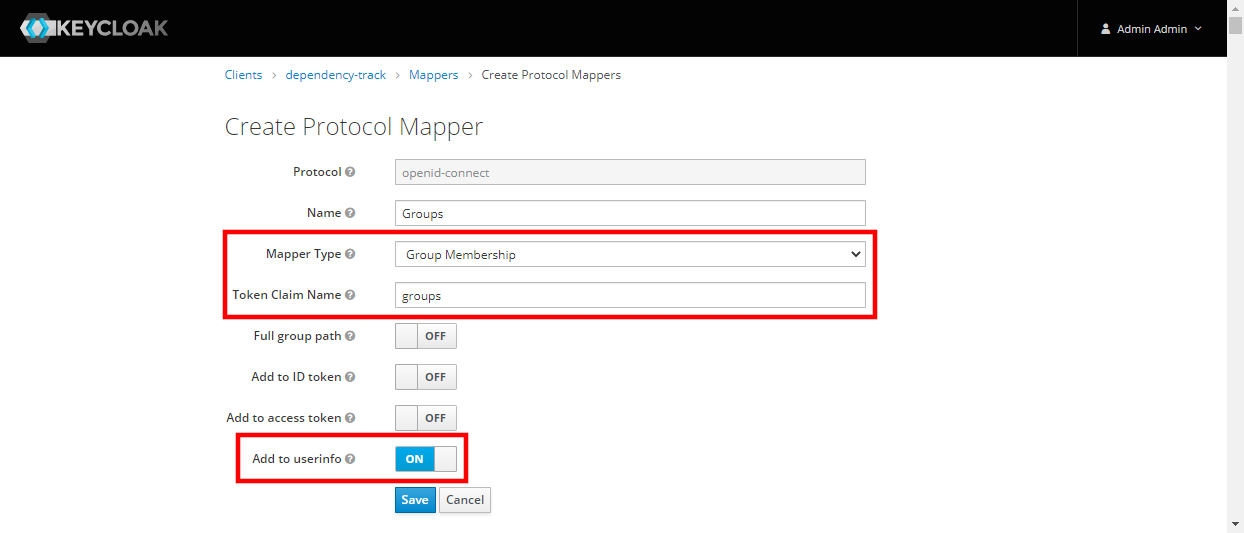
- Mapper Type:
Group Membership - Token Claim Name:
groups - Add to userinfo:
ON
- Mapper Type:
使用
集成和交付
Dependency Track高速处理和分析CycloneDX BOMs,非常适合在modern build pipelines中使用。CycloneDX BOMs的生成通常发生在CI期间或生成最终应用程序集时。由于构建时工具的可用性,CycloneDX是首选的BOM格式,这些格式侧重于安全用例。但是,也支持SPDX tag和RDF格式的BOMs。
访问CycloneDX Tool Center,了解生成CycloneDX BOMs可用工具的信息。
Dependency-Track持续监视组件是否存在已知漏洞。在Dependency-Track中添加或更新组件时,将对该组件执行分析。此操作发生在通过REST或从用户界面接收文件以及更改组件的过程中。Dependency-Track将会保持每天自动分析组件安全。
在Jenkins环境中,推荐使用Dependency Track Jenkins Plugin将CycloneDX BOMs上传至Dependency-Track。
对于其他环境,可以使用cURL(或类似的)。
CycloneDX or SPDX BOM
要发布CycloneDX或SPDX BOMs,请使用有效的API key和项目UUID。Base64对bom进行编码,并将结果文本插入“bom”字段。
|
也可以通过HTTP POST发布BOMs,不需要Base64编码。
|
大型负载
在上传的扫描或BOM较大的情况下,可以优选使用cURLs功能来指定包含有效负载的文件。
|
保持信息透明
Dependency-Track主要关注在SBOMs的消耗和分析上。然而,Dependency-Track也能够从项目集合(portfolio)中的任何项目生成SBOMs。组织能够在客户、合作伙伴或其他利益相关者请求时为项目集合(portfolio)中的任何项目创建SBOMs。
需要更高透明度的组织可以选择使用Dependency-Track通知功能,该功能能够在系统使用或处理SBOM时通过webhook发布SBOMs。当在持续集成或交付环境中使用时,SBOMs可以选择性地发布到一个或多个端点,从而实现与预定方的信息透明。
虽然保持透明是可能的,但应仔细考虑透明度。鼓励各组织首先与同一组织内的其他部门或业务单位共享SBOM数据,然后再与外部各方共享数据。
请参阅通知,以获取有关通过webhooks在 BOM_CONSUMED和 BOM_PROCESSED 上共享的SBOM数据信息。
影响分析
策略制定
分析类型
已知漏洞分析
Dependency-Track集成多个漏洞数据源,识别具有已知漏洞的组件。该平台采用多种漏洞识别方法,包括:
| 分析器 | 描述 |
|---|---|
| Internal | Identifies vulnerable components from an internal directory of vulnerable software |
| NPM Audit | NPM Audit is a service which identifies vulnerabilities in Node.js Modules |
| OSS Index | OSS Index is a service provided by Sonatype which identifies vulnerabilities in third-party components |
| VulnDB | VulnDB is a commercial service which identifies vulnerabilities in third-party components |
上述每种分析器都可以彼此独立地启用或禁用。
Internal Analyzer
内部分析依赖于易受攻击软件的字典。当执行NVD镜像或VulnDB镜像时,将自动填充此字典。内部分析仪适用于所有具有有效CPE的组件,包括应用程序、操作系统和硬件组件。
NPM Audit Analyzer
NPM Audit是一种识别Node.js模块中漏洞的服务。依赖跟踪与NPM Audit service本地集成,以提供高度准确的结果。使用此分析器需要所分析组件的有效的Package URLs。有关更多信息,请参阅NPM Public Advisories (Datasource) 。
OSS Index Analyzer
OSS Index是Sonatype提供的一项服务,用于识别第三方组件中的漏洞。该服务支持广泛的包管理生态系统。Dependency-Track默认与OSS Index集成,提供高度准确的结果。此分析器适用于具有有效Package URLs所有组件。
从Dependency Track v4.0开始,OSS Index默认启用,不需要帐户。对于以前的版本,OSS Index在默认情况下是禁用的,并且需要一个帐户。要启用OSS索引,请注册一个免费帐户,并在Dependency-Track的Analyzers设置的administrative console中输入帐户详细信息。
有关OSS Index漏洞数据更多信息,请参阅OSS Index (Datasource)。
VulnDB Analyzer
VulnDB是Risk Based Security提供的订阅服务。VulnDB分析器能够根据VulnDB服务分析所有CPEs组件。使用该分析器需要组件的CPE信息。
Analysis Interval Throttle
Dependency-Track包含一个内部限制器,用于在执行漏洞分析时防止对远程服务的重复请求。当一个组件Package URL或CPE被成功地用于一个给定的分析器时,时间戳将被记录下来并与interval throttle 进行比较。interval throttle 默认为24小时。
过时组件分析
软件链中使用的具有已知漏洞的组件对依赖于这些组件的项目来说具有重大风险。但是,使用不存在已知漏洞但不是最新版本的组件也存在以下风险:
- 很大一部分漏洞是被发现和修复的,从未通过官方渠道报告过,或者在很晚的时候报告过。使用具有未报告(但仍然已知)漏洞的组件仍然会给依赖它们的项目带来风险。
- 针对组件报告漏洞的可能性相当高。组件在发布之间可能有轻微的API更改,或者在主要发布之间有显著的API更改。保持组件更新是实现以下目的的最佳做法:
- 从性能、稳定性和其他错误修复中获益
- 受益于其他特性和功能
- 受益于持续的社区支持
- 发现漏洞时快速响应安全事件
通过不断更新组件,团队可以更好地在已知影响组件的漏洞时进行快速响应。
许可证评估
作为Dependency-Track策略引擎的一部分,可以根据一个或多个策略评估许可证。
组件标识
作为Dependency-Track策略引擎的一部分,标识包括:
| 标识 | 描述 |
|---|---|
| Coordinates | 匹配包含指定组、名称和版本的组件 |
| Package URL | 匹配指定Package URL的组件 |
| CPE | 匹配指定CPE的组件 |
| SWID TagID | 匹配指定SWID TagID的组件 |
| Hash | 匹配指定Hash的组件 |
- Hash标识自动检测所有已支持的hash算法:
- MD5
- SHA-1
- SHA-256
- SHA-384
- SHA-512
- SHA3-256
- SHA3-384
- SHA3-512
- BLAKE2b-256
- BLAKE2b-384
- BLAKE2b-512
- BLAKE3
使用
基于标识评估组件的通常使用于:
策略包含预定义的允许或禁止的组件列表
识别伪造或已知的恶意组件
完整性验证
Work in progress
数据源
NVD
The National Vulnerability Database(NVD)是最大的公开漏洞信息源。由美国国家标准与技术研究所(NIST)内的一个团队维护,并以MITRE和其他人的工作为基础。NVD中的漏洞称为Common Vulnerabilities and Exposures(CVE)。从20世纪90年代到现在,NVD记录了超过100000个CVEs。
Dependency-Track严重依赖于NVD提供的数据,并包含一个完整的镜像,该镜像每天保持最新,或者在Dependency-Track实例重新启动时加载最新数据。
Credit提供数据来源的部分信息,以及CVE链接。
NVD镜像
Dependency-Track不仅是NVD的使用者,而且还提供NVD镜像功能。此功能内置于Dependency-Track中,不需要进一步配置,镜像每天自动更新。
NVD镜像URL: http://hostname/mirror/nvd
目录列表被禁止提供,但是索引由NVD提供的内容组成。这包括:
JSON 1.1 feed
- nvdcve-1.1-modified.json.gz
- nvdcve-1.1-%d.json.gz
- nvdcve-1.1-%d.meta
(其中%d是从2002年开始的四位数年份)
NPM Public Advisories
NPM public advisories是JavaScript和Node.js漏洞信息的集中来源,NVD中可能记录也可能没有记录。利用Node.js的项目将受益于NPM Audit数据源,因为它提供了对特定于生态漏洞的可见性。
Dependency-Track与NPM集成,使用其public advisory API。Dependency Track能够创建所有NPM advisory数据的镜像。镜像每天都保持最新,或者在重新启动Dependency-Track实例时加载最新数据。
Credit提供数据来源的部分信息,以及NPM advisories链接。
Sonatype OSS Index
Sonatype OSS Index为具有有效的Package URLs的组件提供透明且高度准确的结果。大多数漏洞直接映射到国家漏洞数据库(NVD)中的CVE,但是OSS Index中确实包含许多NVD中不存在的漏洞。
Dependency Track与OSS Index集成,使用其public API。Dependency-Track没有镜像OSS Index,但它会在“as-identified”的基础上识别OSS Index中的漏洞信息。
从Dependency Track v4.0开始,OSS Index默认启用,不需要帐户。对于以前的版本,OSS Index在默认情况下是禁用的,并且需要一个帐户。要启用OSS Index,请注册一个免费帐户,并在administrative的“Analyzers”设置中输入帐户详细信息。
VulnDB
Datasource Routing
Repositories
Internal Components
私有漏洞库
此功能在Dependency-Track v3.x中是实验性的,v4.x中还不可用。
Dependency-Track能够维护自己的内部管理漏洞存储库。私有存储库的行为与其他漏洞信息源(如NVD)相同。

私有漏洞库有三个主要用例。
- 希望跟踪内部开发的组件中漏洞的组织,这些组件在组织中的各种软件项目之间共享。
- 执行安全研究的组织需要在选择性地披露之前记录所述研究。
- 使用非托管数据源来识别漏洞的组织。这包括:
- 更改日志
- 提交日志
- 问题跟踪程序
- 社交媒体信息
私有漏洞存储库中跟踪漏洞的来源为“INTERNAL”。与系统中的其他漏洞一样,需要一个惟一的VulnID来帮助惟一地标识每个漏洞。建议组织遵循相应规则来帮助识别源。例如,NVD中的漏洞都以“CVE-”开头。同样,跟踪自身漏洞的组织可能会选择使用“ACME-”或“INT-”之类的标记,或者根据漏洞的类型使用多个限定符。唯一的要求是VulnID对于INTERNAL是唯一的。
报告结果
审计
状态
抑制
集成
Ecosystem Overview
File Formats
Fortify ssc
Code Dx
Kenna Security
DefectDojo
Notifications
REST API
Dependency-Track is built using a thin server architecture and an API-first design。API是平台的核心。每个API都通过Swagger 2.0完整记录。
http://{hostname}:{port}/api/swagger.json
Swagger UI控制台(平台不包括)可用于可视化和探索各种可能性。Chrome和FireFox扩展可以用来快速使用Swagger UI控制台。
在使用REST APIs之前,必须生成API密钥。默认情况下,创建一个team还将创建相应的API密钥。一个team可能有多个密钥。
ThreadFix
SVG Badges
Community Integrations
最佳实践
常见问题
专业术语
API Key
一串长的随机生成的数字,用于身份验证。所有REST APIs都使用API密钥进行身份验证。API密钥按团队分配。一个团队可能分配了0个或多个API Key。
Auditing
评估调查结果的过程,以确定调查结果的准确性及其对组成部分和项目的影响。审计处理操作创建一个审计跟踪,获取跟踪每一个被发现的行为状态。
Bill of Materials (BOM)
物料清单(BOM)定义并描述了项目软件中使用的内容。在软件供应链中,这是指与软件捆绑在一起的所有组件的内容,包括作者、发布者、名称、版本、许可证和版权。依赖项跟踪支持CycloneDX格式。特定的软件组件的物料清单通常称为SBOM。
Component
将component组件定义为独立实体。组件可以是开源组件、第三方库、第一方库、操作系统或硬件设备。
CPE
Common Platform Enumeration (CPE) 是信息技术系统、软件和软件包的结构化命名方案。基于统一资源标识符(URI)的通用语法,CPE通常包括供应商、产品名称和版本。