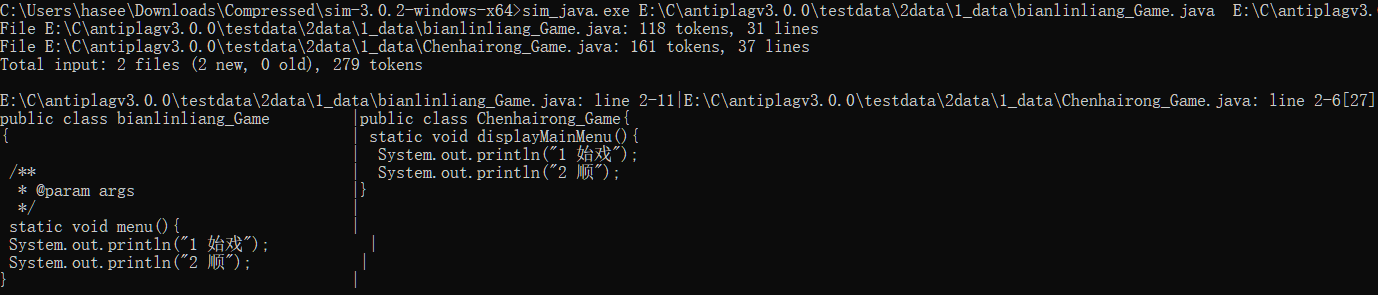
Moss
http://theory.stanford.edu/~aiken/moss/
可本地运行 https://github.com/yangdanny97/OCaMOSS
https://blog.csdn.net/chichoxian/article/details/53115067
使用winnowing算法,
(1)将每个待检测的程序代码分割成长度为k的邻接子字符串,参数k的大小可以由用户自己定义,也可以使用系统默认设置。
(2)利用特定的散列函数散列每一个长度为k的子字符串,得到由所有子字符串构成的散列集。
(3)从生成的散列集中选择出一个能够代表程序代码含义的子集作为该程序代码的程序指纹。
(4)对两个不同程序代码生成的程序指纹进行相似度计算,得到两个程序代码之间的相似度值,作为检测结果。
两个程序代码所生得到的子字符串集中相互匹配的子字符串越多,两个程序代码的相似度也越大。MOSS系统用于检测计算机类程序课程作业中的抄袭行为效果不错。然而,待检测程序代码集中的代码量和代码规模存在较大差异时,如:待检测程序代码中一个程序代码量较大,一个程序代码量较小,MOSS系统的检测准确率将受到很大的影响。MOSS系统所有的处理过程都是在主存中进行的,检测效率不高,难以处理大规模数据。
JPlag
https://github.com/jplag/jplag
报告给出最大相似度和平均相似度两种

支持Java、Python、C、C++,可以添加新的语言
RKR-GST算法:
广义后缀树(GST)算法的简介https://www.cnblogs.com/super-zhang-828/p/5920636.html
(1)将每个程序代码生成相应的标记字符串(token string);
(2)将每个程序代码生成的标记字符串分成更小的称为“tile”的子串,最后对生成的子字符串集两两进行相似度计算,并将匹配成功的子字符串所占全部子字符串的比率转换成两个程序之间相似度的值。相似度计算公式如下:
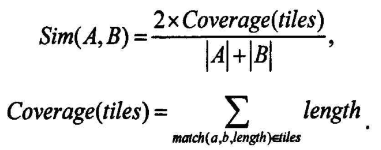
SIM
https://dickgrune.com/Programs/similarity_tester/
https://github.com/andre-wojtowicz/sim
C, C++, Java, Pascal, Modula-2, Miranda, Lisp, and 8086
预处理方式包括对很多变量名替换,修改注释, 改变缩进风格等,经过预处理后,基于标准语法分析树对源程序进行语法分析, 得到一个字符串,并采用一种在DNA序列相似检测中常用的串排列技术进行串匹配,最终返回一个0.0到1.0之间的数值作为两个程序代码之间的相似度结果。Sim系统的运行时间复杂度为O(n),n是系统初始化时所生成的语法分析树的最大长度。Sim系统的检测步骤如下:
(1)通过词法分析器生成能够代表程序代码结构和含义的标记串,每一个标记可以表示一个关键字、一个数字、一个字符串常量、一个注释或一个标识符或一个函数等等。Sim的可扩展性很强,可以较方便地扩展到其他语言;
(2)将所有的程序代码对转化成对应的标记串后,将其中一个程序代码生成的标记串分成几部分,每一部分表示该程序代码的一个模块,然后在另一个程序代码的标记串中匹配每一模块。这样就能更好地检测到重排版和代码块重排序两类类抄袭手段。每次模块匹配后都给出相应的分数,不同的匹配级别给予不同的分数,如:两个模块相匹配记2分,两个模块不匹配记0分等;
(3)利用模块匹配得到的分数计算程序的相似度,并规格化到0.0到1.0之间,计算公式如下:
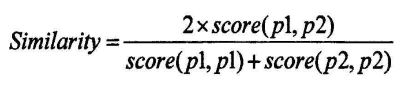
Sim系统用于检测小型计算机类课程作业中的抄袭行为时效果还不错,但Sim系统仅能检测到部分抄袭手段,尤其当程序代码修改较多,结构变化较大时,Sim系统的检测精度明显下降。
Sim系统用于检测待程序代码的数量较少、平均代码量较小时运行速度很快,如:检测56个平均长度为3415字节的程序代码之间的相似性,耗时3.5分钟。但是,待检测程序代码集的平均代码量较大、数量较多时,Sim系统的检测效率会受到不小的影响,运行速度明显降低。
仅可以进行单文件的比较,给出token数量和相似代码片段